학교 과제로 타이타닉 데이터셋을 활용하여 인공신경망 모델을 최적화했다
찾아보니 keras 라이브러리로 만드는 방법 말고는 학습곡선 관련 라이브러리가 아예 존재하지 않는 거다 ㅠㅠ 그래서 모델학습 시킬 때 시키는 횟수를 카운트하여 epoch 수로 정의하고 이때의 개별적 정확도를 측정하여 ggplot2로 그래프를 그렸다
원래는 손실함수 곡선으로 많이 그리는 것 같은데 우리의 것도 내용은 동일하니 유의미한 것 같다 error 값을 그 반대인 accuracy로 대칭시킨 것 뿐이니...
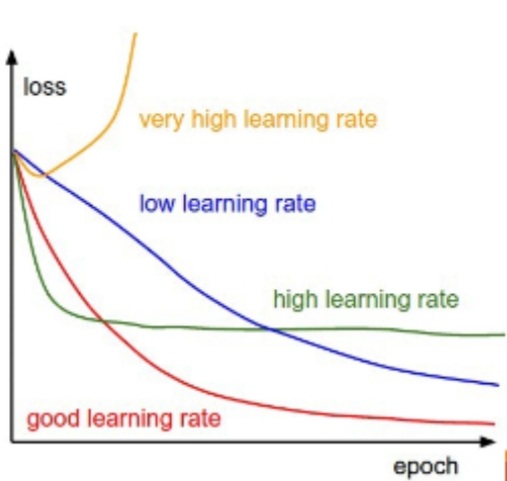
이렇게 learning curve 혹은 loss curve를 치면 판단 방법은 나오는데 코드는 정말 안 나온다..^^;; 그래서 내가 쓴 코드가 혹시 도움이 될까 싶어 ! 이렇게 블로그를 작성하는 것이다
나도 과제로 제출한 것이므로 틀릴 가능성이 있다ㅠ 댓글 주세요ㅠ
쓴 라이브러리 목록인데 안쓴것도 있다
library(dplyr)
library(ggplot2)
library(rpart)
library(rpart.plot)
library(caret)
library(readxl)
library(e1071)
library(nnet)
library(rattle)
library(neuralnet)
library(devtools)
source_url('https://gist.githubusercontent.com/Peque/41a9e20d6687f2f3108d/raw/85e14f3a292e126f1454864427e3a189c2fe33f3/nnet_plot_update.r')
일단 데이터 전처리를 한다
( 결측치를 평균치로 채우고, 타입형을 수치형/factor형으로 바꾸고, 범위를 제한하도록 정규화한다)
reset.seed <- function() {
set.seed(1337)
}
titanic_data = read.csv("titanic3.csv")
#View(titanic_data)
#pclass, survived, sex, age, fare만 추출
titanic<-titanic_data[c(1,2,4,5,9)]
#변수 타입 변환
titanic$pclass <- as.factor(titanic$pclass)
titanic$survived <- as.factor(titanic$survived)
titanic$sex <- as.double(titanic$sex)
titanic$sex[titanic$sex==1] <- 0 #남자
titanic$sex[titanic$sex==2] <- 1 #여자
titanic$age <- as.numeric(titanic$age)
titanic$fare <- as.numeric(titanic$fare)
#titanic = tibble(pclass, survived, sex, age, fare)
#head(titanic)
#str(titanic)
#summary(titanic)
#결측치 처리 -> 평균값으로 대체
mean_age = mean(titanic$age,na.rm=TRUE)
mean_fare= mean(titanic$fare,na.rm=TRUE)
titanic$age = ifelse(is.na(titanic$age),mean_age,titanic$age)
titanic$fare = ifelse(is.na(titanic$fare),mean_fare,titanic$fare)
#View(titanic)
#str(titanic)
#summary(titanic)
# Data preprocessing (정규화) - [0,1] 범위로 값 조정
zs_titanic = preProcess(titanic, method=c("range"))
titanic<-predict(zs_titanic,titanic)
#summary(titanic)
그 다음 데이터를 분리하고(학습용과 예측용)
학습 할 때마다 카운트를 해줘야 하기 때문에 일단 learncurve 데이터프레임을 만든 다음에
반복문 안에서 학습을 시키고
해당 값을 learncurve 데이터프레임에 넣어 주어야 한다
#train set과 test set으로 분리
#test set으로 모델의 성능을 보기 위함
intrain <- createDataPartition(y=titanic$survived, p=0.7, list=FALSE)
titanic_train <- titanic[intrain, ]
titanic_test <- titanic[-intrain, ]
#summary(titanic_train)
#summary(titanic_test)
# 학습곡선
reset.seed()
learncurve <- data.frame(epoch=double(30), acc=numeric(30))
trControl=trainControl(method='repeatedcv', number = 10, repeats = 2)
for (i in 1:30){
learncurve$count[i]<-i
# 학습
fit = caret::train(survived~pclass+sex+age+fare,
data = titanic_train,
method = 'nnet',
maxit = i,
metric = 'Accuracy',
trControl = trControl,
tuneLength = 3
)
# 예측
pred <- predict(fit, titanic_test, type = "raw")
acc_pre <- confusionMatrix(pred, titanic_test$survived)$overall['Accuracy']
learncurve$acc[i] <-acc_pre[1]
}
여기서 nnet 을 method로 하는 train이 자꾸 안 먹혔는데 caret::를 통해 패키지를 다이렉트로 지정해주니 작동되었다
코드를 보면 알 수 있듯이 그냥 데이터프레임에 계속 값을 집어넣는 방식이다
#예측 성능
confusionMatrix(pred, titanic_test$survived)
#그래프
ggplot(learncurve, aes(x=learncurve$count, y=learncurve$acc))+
geom_point()+
geom_line()
성능은 confusionmatrix를 사용하였다
그래프에서는 사실 라벨 이름도 바꿔주고 이것저것 예쁘게 넣어주면 좋은데 귀찮아서 안 넣은 것 맞다...
count 이름을 epoch 그리고 acc 이름을 accuracy로 바꿔주면 좋다
사실 학습곡선이 생각보다 쉬운데! 대부분을 패키지에 의존,,하는 나쁜 버릇을 가진 나는,, 서치가 어려웠다,,결국 내가 다 써야 했지만 나도 참고한 부분이 많고,,,,, 그래서 다른 사람들도 도움이 됐음 좋겠다
그리고 가장 중요한건데 for 문의 범위는 결국 학습 횟수다
난 일단 30으로 했는데 자유롭게 해도 됨
다만 그러면 데이터프레임 크기도 다르게 설정해야하고 또 train 함수의 maxit이 해당 값과 같아야 함(나는 i로 해놔서 상관 없긴 한데 참고하라고)
'Data' 카테고리의 다른 글
| [메모] 데이터 스토리 1 - 6/5/2024 (0) | 2024.06.05 |
|---|---|
| [NLP] Word2vec 유사도분석 및 시각화 연습 (1) | 2021.08.24 |
| [NLP] 플랫폼 구현에 활용되는 짧은 길이의 자연어 처리 기술 (0) | 2021.08.11 |
| [XLNet] XLNet으로 감성분석(sentiment classification, binary categorizing), tokenize 오류 해결 (1) | 2021.08.06 |
| [text classification, categorizing] fasttext, bert로 자연어 분류하고 비교하기 (작성중) (0) | 2021.07.21 |

